1953 年,DNA 结构和功能的发现激发了遗传学的创新–对基因、遗传变异和遗传性的研究。然而,直到最近,遗传学、基因测序和基因编辑的许多基本概念仍难以掌握(Pray,2008 年)。
为了治愈疾病,Emmanuelle Charpentier 和 Jennifer Doudna 开发了一种革命性的基因编辑方法 CRISPR/Cas9,并获得了 2020 年诺贝尔化学奖(NobelPrize.org 2020)。鉴于人们对 CRISPR/Cas9、其机制和应用的广泛好奇,向读者介绍了基因编辑的概况。
在简要回顾核心概念的历史之后,我们将深入探讨不同的基因编辑技术。
历史概述
十九世纪中叶,查尔斯-达尔文和阿尔弗雷德-拉塞尔-华莱士提出了物种是自然选择和进化的产物这一革命性观点,震惊了科学界。他们的假设引出了许多问题。性状是如何从父母传给后代的?解释多样性和同质性的性状表达的基础是什么过程?
孟德尔(Gregor Mendel)对豌豆植物的实验回答了一些问题,特别是植物的高度和颜色等性状随亲本性状的变化而变化。孟德尔生前曾受到一些误解,但当生物学家威廉-贝特森(William Bateson)在遗传学研究中创造了 “遗传学 “一词(贝特森,1905 年)后,孟德尔的研究成果重新受到重视。在孟德尔的研究之前,大多数科学家都认为后代的性状是亲代性状的平均值(Bulmer,1999 年)。然而,如果是这样的话,每个性状都会在多代之后趋同于其平均值。换句话说,”平均 “理论无法解释物种内部和物种之间的多样性。与此相反,孟德尔的遗传定律表明,后代的性状是离散贡献的函数,每个性状来自每个亲代。
孟德尔定律并没有解答有关遗传的其他问题 1869 年,弗里德里希-米舍尔分离出核酸(DNA 的主要组成成分之一),但直到 1944 年,奥斯瓦尔德-艾弗里、科林-麦克劳德和麦卡蒂操纵细菌的细胞内容,才证明 DNA 是遗传信息的储存库(普雷,2008 年)。甚至在发现 DNA 在遗传中的作用之前,科学家们就已经明白,细胞在体细胞(无性生殖)和有性生殖过程中都会交换遗传物质(科恩,2018 年)。
确定 DNA 是支配生物系统的遗传内容,是了解遗传密码功能的第一步。20 世纪 50 年代,詹姆斯-沃森(James Watson)、弗朗西斯-克里克(Francis Crick)、罗莎琳德-富兰克林(Rosalind Franklin)和莫里斯-威尔金斯(Maurice Wilkins)揭示了分子水平的 DNA,使科学家们在基因测序和编辑方面取得了进展。
DNA 序列编码特定蛋白质的合成,这些蛋白质支配着身体的各种过程,这种关系被称为 “中心教条”(Central Dogma)。反过来,”中心教条 “又提出了更多的问题。
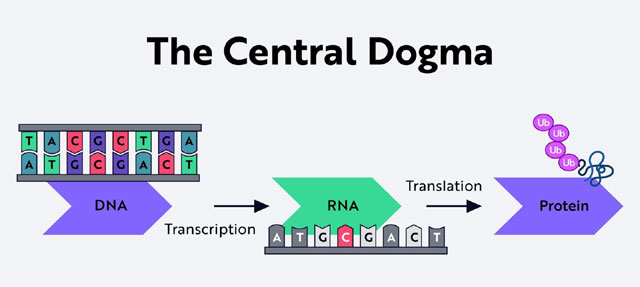
我们如何操纵 DNA 序列来改变生物过程或功能?
遗传学的科学进展

核心概念
支配生物系统的基本分子是什么?本节按物理大小顺序对它们进行说明。
细胞: 细胞是我们体内最小的生命单位(美国国家癌症研究所,2011 年)。我们的身体容纳着高度特化的活细胞。例如,皮肤和血液就是由数万亿个细胞分化而成的,这些细胞具有不同的功能。

从干细胞、血细胞、神经细胞到脂肪细胞,我们的约 200 种细胞类型中的每一种都有一个微型的器官状结构,称为细胞核,其中的染色体包含遗传信息(巴克斯特 2021)。

染色体 我们的遗传信息非常复杂,被组织成称为染色体的结构。每个人体细胞的细胞核内有 23 对染色体,即 46 个独立的结构。细菌通常只有一个 DNA 分子,而草莓每个细胞可能有 56 条甚至 70 条染色体(Hummer 等,2009 年)。

基因 每条染色体就像一个市场,里面有不同的存储空间或称为基因的部分。基因通常包含合成蛋白质的指令,但有些基因根本没有用处。基因组是一套完整的基因或遗传信息,但人类基因组中只有 1-2% 包含编码蛋白质的基因。换句话说,”存储空间 “中约 99% 的 “商店 “是 “闲置 “的,或者说是不起作用的(Henninger,2012 年)。科学家估计,人类拥有约 20,000 个基因。

基因活化是所有生物体发展和运作的基础,它同时实现了多样性和同质性。例如,一个人的外表、健康状况和性格可能与她的朋友大相径庭,但这两个朋友的基因组之间的共同点要比大象多得多。
虽然一个基因可以决定一种性状–例如亨廷顿氏病(Bhattacharyya,2008 年)–但多个基因和环境决定了大多数性状。单个基因也可以影响多个性状(Lobo,2008 年)。
蛋白质:基因如何决定性状?从技术上讲,基因拥有编码蛋白质的指令。蛋白质是由称为氨基酸的构件组成的有机化合物,在细胞的生长和维持过程中发挥着特定的重要作用(EUFIC 2019)。

蛋白质是人体的主要劳动力:它们控制着人体的大部分结构,执行化学反应,处理信号和信息(Ahlgren 2021)。没有它们,生命将停止运转。

DNA 要了解 DNA,就必须了解染色体。染色体由 DNA 和其他将 DNA 固定在一起的分子组成。基因是根据 DNA 的指令编码蛋白质的特定区域。DNA 由两条链组成,呈阶梯状连接,阶梯状结构又扭曲成双螺旋。
DNA 碱基: DNA 梯子的每一级都由两个分子通过氢键连接而成。DNA 由四种主要分子组成:腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤。腺嘌呤总是与胸腺嘧啶配对,胞嘧啶总是与鸟嘌呤配对。这些分子(或 “碱基”)以及它们出现的顺序,提供了细胞组织各种氨基酸所需的遗传密码–指令。当氨基酸结合在一起时,就构成了特定的蛋白质。它们共同为生命提供动力。


RNA 在人类体内,RNA 是一种单链化合物,在 DNA 和氨基酸之间传递信息(克兰西和布朗,2008 年)。要理解这一过程,可以考虑这样一个比喻。想象一位只会说英语的老师,而她的学生都只会说西班牙语。讲英语的老师希望她的学生按照姓氏的字母顺序排成一队。幸运的是,她的西班牙语朋友可以翻译这个要求。在这个例子中,讲英语的老师就好比是 DNA,而讲西班牙语的朋友就好比是 RNA,每个孩子就好比是一个氨基酸,而整排孩子就好比是蛋白质。

基因编辑: 基因编辑入门
基因编辑的潜力有多大?
基因编辑有可能治愈一系列危及生命的遗传疾病。以囊性纤维化为例。什么是囊性纤维化,基因编辑如何帮助囊性纤维化患者?
1. 让我们从一个简单的例子开始。在细胞中特定染色体的某一点上,大多数人的 DNA 序列都是这样的:

2. 然后,我们用这个 DNA 序列来识别一个人:

对于我们假想宇宙中的大多数人来说,AAA DNA 序列编码的是一种叫做苯丙氨酸的特定氨基酸。而对于独特的人来说,AAT DNA 序列编码的是一种叫做亮氨酸的氨基酸。随着数以万亿计的细胞不断繁殖和合成蛋白质,这个简单的错误可能会导致毁灭性的后果(Drummond 和 Wilke,2009 年)。
3. 现在,考虑一下这个 DNA 序列位于一个叫做 CFTR 基因的区域,该基因负责制造一种叫做囊性纤维化跨膜传导调节因子的蛋白质。这种调节因子能促进颗粒通过细胞壁的运输,而细胞壁会产生粘液、汗液和其他生物物质(Winikates,2012 年)。AAA DNA序列产生苯丙氨酸以合成CFTR蛋白,而AAT序列则产生亮氨酸–可以说是错误的,因为没有苯丙氨酸,CFTR基因就不能正常产生CFTR蛋白,从而导致囊性纤维化(加拿大药物和卫生技术局,2018年)。
4. 我们知道 AAA DNA 中的某些部分导致了囊性纤维化。如果我们能锁定这组细胞中 AAA DNA 的突变部分,对其进行必要的改变,让细胞分裂,然后用无错误的细胞取代所有出错的细胞,会怎么样呢?换句话说,如果我们可以编辑 DNA,使其正确进化,而不是产生囊性纤维化呢?
这个简化的假设问题为我们深入探讨不同的基因编辑技术及其部分应用做好了准备。
什么是基因编辑?
20 世纪 70 年代,鲁道夫-杰尼施(Rudolf Jaenisch)和比阿特丽斯-明茨(Beatrice Mintz)将病毒 DNA 注入小鼠胚胎(杰尼施和明茨,1974 年),基因工程开始兴起。20 世纪 80 年代,三组科学家开发出了一种靶向和停用特定小鼠基因的方法(NobelPrize.org,2007 年)。
这种方法依赖于一种叫做同源重组的过程,在这一过程中,相似的染色体会相互交换 DNA 序列或 RNA(对于病毒而言),从而在此过程中增加基因变异(Masood 等人,2016 年)。科学家发现,外来 DNA 与哺乳动物细胞的染色体之间也会发生类似的相互作用(NobelPrize.org,2007 年)。这种方法表明,消除基因组突变引起的疾病是可能的。科学家们随后开始研发更有效的靶向基因的方法(伍尔夫,1998年)。
基因编辑方法: 巨核酸酶
巨核酸酶是一种能识别 12 到 45 个碱基对的 DNA 序列并能在特定位点切割 DNA 的酶。20 世纪 90 年代,科学家发现这些酶对基因工程非常重要(Epinat 等人,2003 年),它们就像 “剪刀”,能在特定 DNA 位置产生断裂,从而完全替换序列或在断裂处插入新碱基。
由于巨核酸酶以大序列为目标,其应用受到限制,因为在基因中找到大的特定序列的几率很低。因此,科学家们正在通过修改目标DNA序列或创造人工巨核酸酶,不断发展和扩大巨核酸酶的目标序列库(Hoy,2013年)。
通过基因核酸酶进行基因工程的示例

由于巨核酸酶具有高度特异性,因此其工作难度大、成本高,但这并没有阻碍其发展。目前,生物技术公司 Precision Biosciences 正在进行一项第一阶段临床试验,研究专门设计的巨核酸酶对非霍奇金淋巴瘤的疗效(O’Hanlon Cohrt 2021)。巨核酸酶能识别特定的 DNA 序列,具有细胞毒性低的优点:与其他基因编辑技术相比,巨核酸酶在脱靶或不正确的位置切割 DNA 的风险较低(Paques 和 Duchateau,2007 年)。
基因编辑方法: 锌指核酸酶(ZFNs)
巨核酸酶能在高度特异的位点切割 DNA,而锌指核酸酶则能针对科学家使用乐高类结构锌指指定的多达 18 个碱基对(Martinez-Lage 等人,2017 年)。锌指是与不同 DNA 序列结合的天然蛋白质结构(Klug,2010 年)。
每个锌指可以识别三到四个碱基对的 DNA 序列,当它们结合在一起时,可以识别并结合到长度为 24 个碱基对或更长的特定 DNA 序列上(Kim 等,2009 年)。在基因工程应用中,锌指通常比巨核细胞酶更灵活。科学家们将锌指与一种类似于巨核酸酶但特异性低于巨核酸酶的 DNA 切割酶结合起来,创造出了 ZFNs,能以前所未有的精度靶向切割各种 DNA。
尽管如此,锌指核酸酶也并非没有风险。如果锌指对目标 DNA 序列的特异性不够,核酸酶就会在非预期、非目标位置无意地切割 DNA,从而可能完全杀死细胞(Cornu 等人,2008 年)。虽然寻找对目标 DNA 序列具有足够特异性的锌指一直很困难,但最近对增强型锌指工程技术的投资正在解决这些问题(Paschon 等人,2019 年)。
2021 年,来自加利福尼亚和澳大利亚的一组研究人员发表了一项探索锌指蛋白在抑制 HIV-1 表达方面疗效的研究,该研究结果前景看好,而不是强迫 HIV 阳性患者接受紧张的治疗(Shrivastava 等人,2021 年)。此外,正在开发基于 ZFN 的基因编辑技术以治疗镰状细胞病的 Sangamo Therapeutics 公司发布了对三名接受基因编辑细胞疗法治疗镰状细胞病的患者进行 I/II 期治疗的积极结果(Philippidis 2021)。
通过 ZFNs 进行基因工程的示例

基因编辑方法: 转录激活剂样效应核酸酶(TALENs)

TALEN 与 ZFN 有一个关键区别:每个锌指能识别目标序列上的多个碱基(通常是三个),而每个类转录激活因子效应蛋白(TALE)只能识别一个碱基。因此,科学家们可以创造出能识别基因组中特定序列的结构(Yeadon,2014 年)。2010 年,爱荷华州立大学的研究人员开发出了将 TALE 蛋白与 DNA 切割酶相结合的方法,并创造出了比 ZFN 更灵活的替代品(Christian 等人,2010 年)。
自首次发现以来,TALENs 已被广泛用于改造各种植物的基因组。2014 年,一组研究人员利用 TALENs 在大豆的两个基因中引入突变,使其种子将单不饱和脂肪转化为多不饱和脂肪,从而使人类饮食中的大豆更健康(Haun 等,2014 年)。农业技术公司 Calyxt 自 2010 年成立以来,一直在利用 TALENs,目前正在开发可在寒冷气候下生长的燕麦(Calyxt 2021)。
TALENs 也正在开发用于人体。例如,生物技术公司 Cellectis 使用 TALENs 编辑供体白细胞(T 细胞)的基因,并将其植入白血病和多发性骨髓瘤患者体内(Cellectis 2021)。
利用 TALENs 进行基因工程的示例

基因编辑方法: CRISPR(簇状规则间隔短联合重复序列)+ Cas9 蛋白质

与上述技术不同,CRISPR/Cas9 不需要科学家花时间构建新的蛋白质结构来靶向特定的 DNA 序列。相反,他们可以编程一个答案钥匙–单导RNA(sgRNA)–来瞄准特定的DNA序列。当与一种名为 Cas9 的 DNA 切割蛋白结合时,CRISPR/Cas9 可以实现最高效、最灵活的基因编辑。虽然 CRISPR Cas9 是第一个被发现和研究的酶,但其他 Cas 酶也有不同的特性。
DNA 中的 “串联重复序列 “指的是 DNA 碱基中彼此相邻的重复、可识别的模式(美国国家人类基因组研究所,2021 年)。例如,”CATCATCATCAT “和 “AGAGAGAGAG “序列就是串联重复序列。20 世纪 80 年代,科学家发现了大肠杆菌基因组中的重复序列,与大多数串联重复序列不同的是,这些重复序列被间隔序列(或将两个活性基因彼此分开的 DNA 片段)隔开(Vidyasagar 和 Lanse,2021 年)。这些序列也是回文序列,即梯子的一部分序列与梯子另一侧的反向序列相同。

对这些神秘重复序列的研究发现:(1) 这些 “重复 “存在于许多其他细菌和古细菌中;(2) 这些序列与产生 DNA 切割蛋白的其他基因有某种联系(莫希卡等人,2000 年)。到 2007 年,研究人员将 CRISPR 在细菌中的功能概念化为对外来病毒先前攻击的记忆库(Barrangou 等人,2007 年)。在受到病毒攻击后,细菌会将病毒基因组的某些部分作为间隔序列纳入自身的 DNA 中,这样在未来的攻击中,细菌就可以在 CRISPR RNA(crRNA)和反式激活 RNA(tracrRNA)的帮助下,利用细菌已经储存的序列来指导 DNA 剪接蛋白(Cas9 蛋白)切割病毒基因组的某些部分(Deltcheva 等人,2011 年;Jinek 等人,2012 年;Vidyasagar 和 Lanse,2021 年)。
这些细菌就像联邦法官。病毒第一次犯罪–病毒攻击–法官和陪审团将决定它是否有罪。然后,如果另一种具有相同 RNA 的病毒犯下同样的罪行,法官就有了先例–CRISPR 空间序列的形式–可以更有效地给新病毒定罪。
2012 年,两组科学家意识到,细菌靶向和切割 DNA 的机制可用于包括人类在内的其他物种,即通过手动编程使 crRNA 靶向任何所需的 DNA 序列。诺贝尔奖获得者埃马纽埃尔-查朋蒂埃(Emmanuelle Charpentier)、詹妮弗-杜德娜(Jennifer Doudna)和他们的同事找到了一种方法,将crRNA和tracrRNA结合成单一的引导RNA(sgRNA)(Gasiunas等人,2012年;Jinek等人,2012年),从而使这一过程变得更加简单。这一发现让三组科学家在 2013 年找到了在体内或活生物体内进行 CRISPR/Cas9 基因编辑的方法(Cong 等人,2013 年;Jinek 等人,2013 年;Mali 等人,2013 年;Seladi-Schulman,2019 年)。在此之前,所有 CRISPR/Cas9 实验都是在体外进行的,即在生物体外的试管或培养皿中进行的(Seladi-Schulman,2019 年)。
利用 CRISPR Cas9 进行基因工程的示例

基因编辑过程中会发生什么?
重要的是,所有基因编辑方法的实际基因编辑过程大致相同,如下图所示。
基因编辑示意图


如今,CRISPR 在科学文献和临床试验中主导着基因编辑。与 ZFN 和 TALENs 相比,CRISPR 更为高效、有效和经济。
碱基编辑和基质编辑
由于CRISPR的风险在于脱靶编辑,刘大卫和博士后研究人员亚历克西斯-科莫尔(Alexis Komor)和妮可-高德利(Nicole Gaudelli)(科莫尔等人,2016年)在CRISPR/Cas9的基础上,于2016年开创了碱基编辑技术。只改变DNA序列中的一个碱基,科学家利用碱基编辑将另一种特殊的酶附加到Cas9蛋白上,靶向序列中的一个特定碱基,然后切换到另一个碱基。因此,科学家没有引入外来DNA,也没有依赖同源检测修复(HDR,见脚注5)。

2019 年,David Liu 和 Andrew Anzalone 进一步增强了 CRISPR/Cas9 的功能(Anzalone 等人,2019 年)。碱基编辑每次只能替换一个 DNA 碱基,而素数编辑则可以一次插入、删除和替换多个碱基。质粒编辑使 RNA 能够在目标链上合成额外的 DNA 碱基,而不是将 RNA 的作用局限于识别正确的 DNA 序列。换句话说,基质编辑具有碱基编辑的所有优点–不依赖 HDR 或有缺陷的修复机制–而且更加灵活。与传统的 CRISPR/Cas9 相比,它的特异性更高(Anzalone 等人,2019 年)。
基序编辑示例

与其他基因编辑方法相比,碱基和质粒编辑具有明显的优势。重要的是,它们不会将染色体切割成碎片,也不会造成 DNA 双链断裂。此外,虽然传统的 CRISPR Cas9 可以破坏基因,但与质粒编辑和碱基编辑不同,它不能纠正基因。
在寻找遗传疾病治疗方法的过程中,CRISPR/Cas9、碱基编辑和素材编辑已经占据了中心位置。CRISPR Therapeutics、Caribou Biosciences、Beam Therapeutics 和 Prime Medicine 等公司正在进行试验,以确定这些技术如何消除遗传疾病,改善人类健康。密歇根大学的研究人员最近发表了关于使用 CRISPR/Cas9 靶向小鼠棕色脂肪细胞的研究,希望以此来治疗人类肥胖症(Romanelli 等,2021 年)。哈佛大学和麻省理工学院的研究人员刚刚开发出一种名为 TwinPE 的素材编辑方法,允许科学家插入或交换人类的整个基因(Anzalone 等人,2021 年)。他们的实验室还首次开发出了对线粒体 DNA 进行碱基编辑的方法(Mok 等,2020 年)。今年,英国广播公司(BBC)报道称,英国大奥蒙德街医院(GOSH)通过治疗患有T细胞急性淋巴细胞白血病的阿丽莎(Alyssa)证明了碱基编辑的潜力,阿丽莎在接受试验的碱基编辑CARTs治疗后病情得到缓解。
结论
过去四十年的科学进步使基因编辑变得更加准确、高效和经济,但许多问题,特别是有关基因表达和性状的问题,仍然没有答案。围绕 CRISPR/Cas9、碱基编辑和质粒编辑的创新改进了基因编辑,为科学家绘制人类基因组复杂的相互关系图提供了许多令人兴奋的机会。